🎙️ Créer un générateur vocal en local avec Piper et Flask (sans prise de tête !)
Tim
February 21st, 2025
Créer son propre générateur vocal avec Piper et Flask (sans prise de tête !)
On vit une époque où les IA vocales sont partout : assistants vocaux, livres audio, vidéos narrées… et pourtant, beaucoup d’entre elles sont payantes et hébergées sur le cloud (coucou ElevenLabs 👋).
Mais et si on pouvait générer des voix naturelles en local, sans dépendre d’un service externe ?
💡 Bonne nouvelle : c’est possible avec Piper !
Dans cet article, je vous montre comment j’ai créé une petite application Flask qui transforme du texte en audio en local, avec des voix de qualité, sans abonnement, et sans se compliquer la vie.
Prêt ? Let’s go ! 🎙️
Pourquoi un TTS local ?
Avant d’entrer dans le vif du sujet, pourquoi se compliquer à installer un TTS en local alors qu’il existe des services ultra-performants ?
⚡ C’est léger et rapide : Piper tourne même sur un petit PC.
☁️ Aucune dépendance au cloud : pas besoin d’être connecté.
📖 C’est gratuit et open source : pas d’abonnement, pas de restriction.
💡 Idéal pour des projets persos ou une intégration rapide.
Bien sûr, si vous cherchez une qualité de voix ultra-réaliste, ElevenLabs reste une solide option. Mais ici, le but est de se faire la main et de bricoler quelque chose de fonctionnel rapidement et en local.
1️⃣ Installer Piper sur Windows
Télécharger Piper
Piper est disponible sur GitHub :
🔗 https://github.com/rhasspy/piper
Téléchargez la version adaptée à votre OS. Pour Windows, il y a une version précompilée qui facilite l’installation.
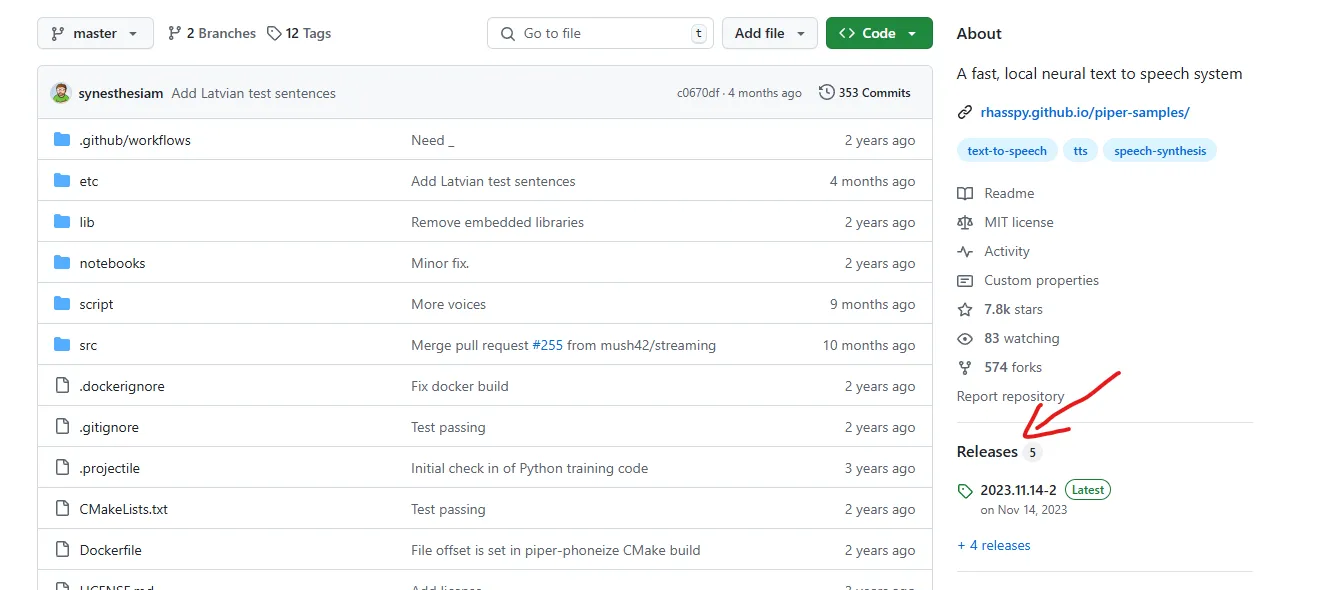
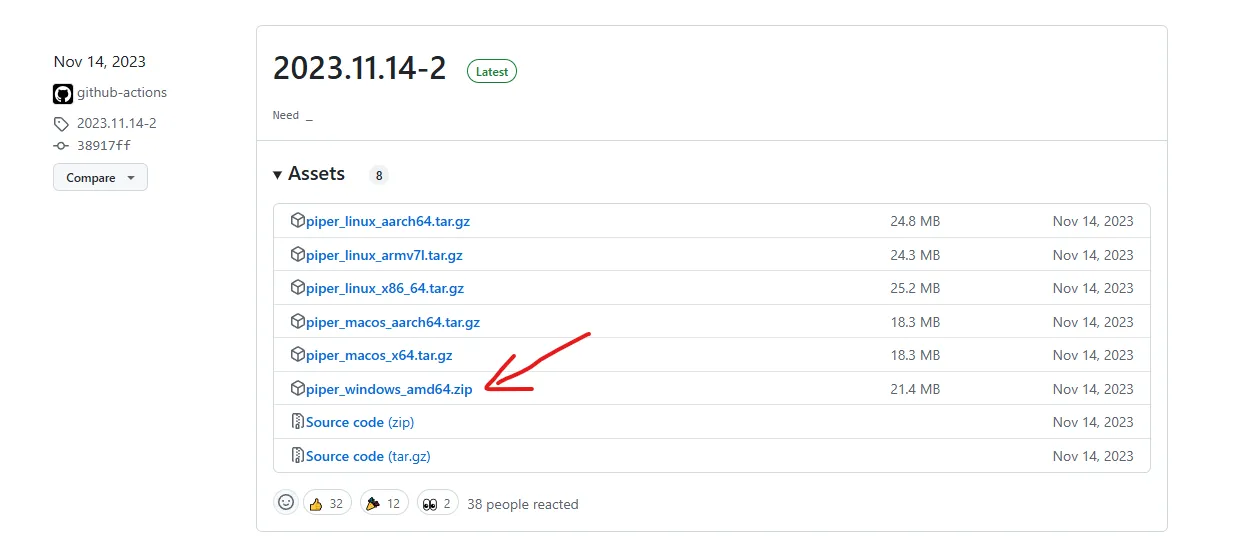
Installer Piper
Une fois téléchargé, il suffit d’extraire le dossier et d’ouvrir un terminal dedans. Ensuite, testons si Piper fonctionne bien avec :
# Je suis sous Windows donc la commande ressemble à ceci
.\piper --helpSi tout va bien, Piper est prêt ! 🎉
Téléchargement et installation des modèles
Une fois Piper installé, il faut lui fournir un modèle de voix pour qu’il puisse générer du son. Chaque modèle se compose deux fichiers essentiels :
Le fichier modèle (
.onnx) → Contient les données nécessaires à la synthèse vocale.Le fichier de configuration (
.json) → Définit les paramètres du modèle (vitesse, intonation, etc.).
Les modèles de voix pour Piper sont disponibles ici :
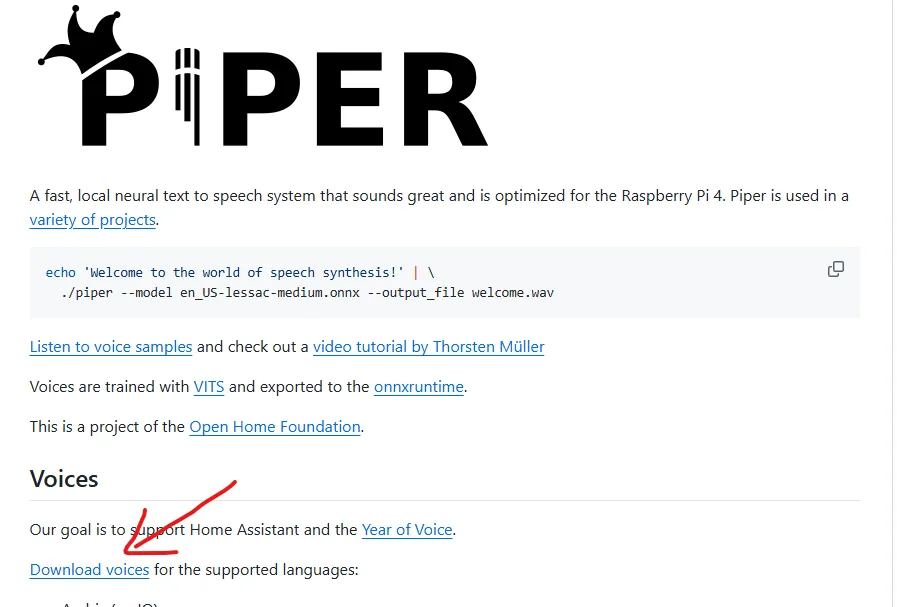
Chaque langue dispose de plusieurs voix, souvent nommées d’après leur créateur. Choisissez celle qui vous plaît, téléchargez les deux fichiers (.onnx et .json) et placez-les dans le dossier piper/models/.
💡 Exemple pour une voix en français :
Si vous téléchargez "fr_FR-gilles", vous aurez :
fr_FR-gilles-low.onnxfr_FR-gilles-low.onnx.json
Placez-les dans :
📂 piper/models/
Et voilà, votre modèle est prêt à l’emploi ! 🎙️
Quelle version du modèle choisir ?
En explorant les modèles, vous remarquerez généralement plusieurs versions d'une même voix : low, medium, high, vits, vits-high, etc.
Low → Modèle léger, rapide à exécuter, mais qualité audio réduite.
Medium → Bon compromis entre rapidité et qualité.
High → Meilleure qualité vocale, mais plus gourmand en ressources.
VITS → Version plus avancée avec une intonation plus naturelle.
💡 Si vous cherchez un bon équilibre, partez sur Medium. Si vous voulez une qualité optimale et que votre machine le permet, essayez High ou VITS-High.
📌 Astuce : Rien ne vous empêche de télécharger plusieurs versions et de tester ! 🚀
Testez ensuite une synthèse vocale rapide :
echo "Le métier de développeur est fascinant!" | .\piper --model models\fr\fr_FR-gilles-low.onnx --output_file test.wavPetites précisions utiles
Avant d’exécuter la commande, voici deux petites choses à savoir :
1️⃣ Organisation des modèles
J’ai créé un dossier models/ et, à l’intérieur, j’ai classé les modèles par langue (fr/, en/, es/, etc.). Cela permet de s’y retrouver facilement quand on télécharge plusieurs voix. C’est pour ça que le chemin du modèle dans la commande est un peu long :
models\fr\fr_FR-gilles-low.onnx2️⃣ Exécution sous PowerShell
Si vous utilisez PowerShell, vous devrez ajouter .\ devant piper, sinon il vous affichera un avertissement indiquant que la commande doit être explicitement référencée. D’où :
echo "Le métier de développeur est fascinant!" | .\piper --model models\fr\fr_FR-gilles-low.onnx --output_file test.wavSi vous êtes sous cmd, pas besoin du .\, un simple piper suffit. 🚀
Si vous entendez votre fichier test.wav, tout fonctionne. 🚀
2️⃣ Intégrer Piper dans une application Flask
Bon, Piper c’est cool en ligne de commande, mais ce serait mieux avec une interface. 🖥️
J’aurais pu faire une solution bien robuste avec Laravel et une file d’attente, comme j’en ai l’habitude, mais ici, l’objectif était avant tout d’aller vite et de m’amuser avec Python, sans prise de tête. Pour être honnête, ça faisait un bon moment que je n’avais pas touché à Python… et ça commençait à me manquer ! 😄
Installation des dépendances
On crée un environnement virtuel et on installe Flask :
python -m venv .venvUne fois l'environnement virtuel créé, il faut l'activer pour qu'il devienne l'environnement Python par défaut pour votre projet. Cela garantit que toutes les dépendances seront installées et exécutées dans cet environnement isolé.
# Sous Windows
.venv\Scripts\activate
# Sous Linux
source .venv/bin/activateCette commande active l'environnement virtuel en exécutant le script activate situé dans le dossier Scripts.
Maintenant que l'environnement virtuel est activé, vous pouvez installer les dépendances dont vous avez besoin pour le projet. Dans ce cas, nous allons installer Flask et python-dotenv.
pip install flask python-dotenvCréer une API Flask
On va à présent créer un petit serveur Flask qui recevra du texte et retournera un fichier audio.
👉 Route pour générer l’audio
👉 Stockage des fichiers dans un dossier statique
👉 Listing des fichiers générés
Le tout en mode asynchrone, pour éviter de bloquer l’application.
L’objectif ici n'est pas de faire un tutoriel complet sur Flask, mais plutôt de vous montrer comment j'ai intégré Piper dans une application web. Pour ceux qui souhaitent explorer l’ensemble du code, vous pouvez consulter le dépôt GitHub ici.
Dans cette section, je vais vous montrer la classe business, qui est la classe TextToSpeech. C’est elle qui gère la logique de génération de la parole avec le modèle Piper. C'est le fichier principal du backend, et il contient toute la logique nécessaire pour interagir avec Piper et générer des fichiers audio.
import os
import subprocess
import re
import unicodedata
class TextToSpeech:
def __init__(self, piper_path, models_dir, root_folder):
"""Initialize the TextToSpeech object with Piper executable path and models directory."""
self.piper_path = piper_path
self.models_dir = models_dir
self.root_folder = root_folder
def get_languages(self):
"""Dynamically load languages from the models directory."""
return [lang for lang in os.listdir(self.models_dir) if os.path.isdir(os.path.join(self.models_dir, lang))]
def get_models_for_language(self, language):
"""Get all models for a given language."""
language_path = os.path.join(self.models_dir, language)
return [f for f in os.listdir(language_path) if f.endswith('.onnx')]
def get_safe_filename(self, text, n = 50):
"""Generate a safe, slugified filename based on the input text."""
# Normalize the text to remove accents
normalized_text = unicodedata.normalize('NFKD', text[:n]).encode('ascii', 'ignore').decode('ascii')
# Replace non-alphanumeric characters (except spaces) with an empty string
slugified_text = re.sub(r'[^a-zA-Z0-9\s]', '', normalized_text)
# Replace spaces with hyphens and convert to lowercase
safe_text = re.sub(r'\s+', '-', slugified_text).lower()
return f"static/audio/{safe_text}.wav"
def generate_speech(self, text, model_path, output_file, rate=1.0):
"""Run the Piper executable to generate speech from text."""
output_file = os.path.join(self.root_folder, output_file)
# Define the correct command for Piper
command = f'"{self.piper_path}" --model "{model_path}" --output_file "{output_file}" --rate {rate}'
print('-- 05 -> Command: ', command)
try:
# Run Piper with the given command
process = subprocess.run(command, shell=True, text=True,
input=text, capture_output=True, encoding='utf-8'
)
print('-- 06 -> Process started successfully: ', command)
if process.returncode != 0:
raise Exception(f"Error running Piper: {process.stderr}")
except Exception as e:
print(f"Error in generate_speech: {e}")
raise
def process_speech_request(self, text, selected_language, selected_model, rate=1.0):
"""Process the text-to-speech request and return the output file path."""
model_path = os.path.join(self.models_dir, selected_language, selected_model)
if not os.path.exists(model_path):
raise FileNotFoundError(f"Model not found at {model_path}")
output_file = self.get_safe_filename(text)
self.generate_speech(text, model_path, output_file, rate)
return output_file3️⃣ Une interface web minimaliste avec Alpine.js
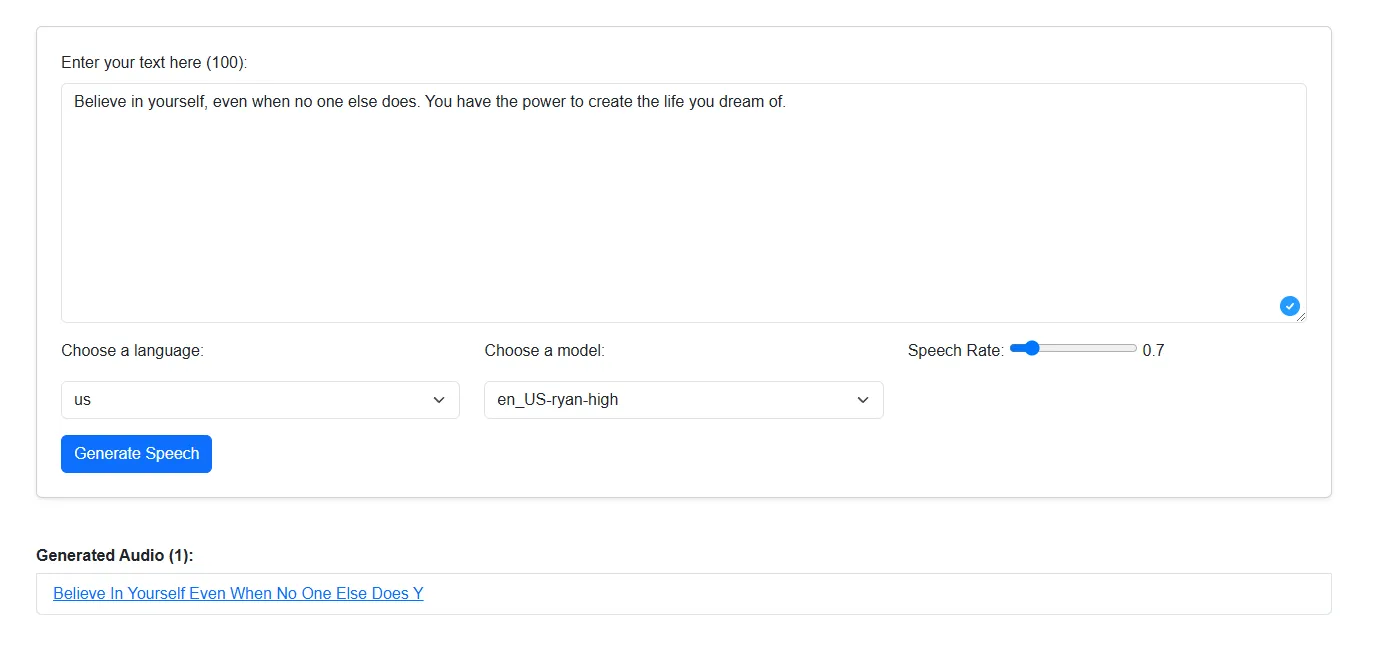
Plutôt que de faire un gros front avec Vue ou React, j’ai choisi Alpine.js pour garder un projet simple et léger.
On a donc une page HTML qui :
✅ Permet d’entrer du texte
✅ Choisir la langue et le modèle
✅ Générer l’audio en arrière-plan
✅ Afficher la liste des fichiers disponibles
Et tout ça sans recharger la page. ✨
4️⃣ Gestion des tâches en arrière-plan
La génération de la parole peut prendre un certain temps, notamment si le modèle est complexe ou si le texte est long. Pour éviter que l'application ne devienne lente ou qu’elle se fige pendant ce processus, il est essentiel d'effectuer cette tâche en arrière-plan.
Sur des applications plus robustes comme celles développées avec Laravel, il serait courant d'utiliser une file d'attente (queue worker) pour gérer cela, mais dans notre cas, l'objectif était de tester rapidement Python tout en maintenant la simplicité. Nous avons donc opté pour un thread qui exécute la tâche de génération de la parole en arrière-plan, ce qui permet à l’utilisateur de continuer à interagir avec l’application sans interruption.
Voici le code que j’utilise pour gérer cette tâche dans Flask :
def generate_speech():
if request.method == "POST":
text = request.form.get("text")
selected_language = request.form.get("language")
selected_model = request.form.get("model")
rate = float(request.form.get("rate", 1.0)) # Default rate is 1.0 if not provided
task_id = str(uuid.uuid4()) # Generate a unique task ID
with current_app.app_context(): # Pushing app context
text_to_speech = current_app.config['TEXT_TO_SPEECH']
thread = threading.Thread(target=background_generate_speech, args=(text_to_speech, task_id, text, selected_language, selected_model, rate))
thread.start()
return jsonify({"task_id": task_id, "status": "Processing in the background..."})Dans cette partie du code, lorsque l'utilisateur soumet une requête pour générer un fichier audio, celle-ci est traitée dans un thread séparé. Le processus ne bloque donc pas l'application et l'utilisateur reçoit immédiatement une réponse indiquant que le processus est en cours.
Ensuite, la tâche est réellement exécutée dans la fonction background_generate_speech() :
def background_generate_speech(text_to_speech, task_id, text, selected_language, selected_model, rate):
"""Run speech generation in the background and update status."""
# Manually push the app and request context for the background thread
save_task_status(task_id, "processing")
try:
# Process the speech request and save output file path
output_file = text_to_speech.process_speech_request(text, selected_language, selected_model, rate)
save_task_status(task_id, "completed")
except Exception as e:
save_task_status(task_id, f"failed: {str(e)}")
return str(e)Cette approche présente plusieurs avantages :
Réactivité : L'utilisateur n'attend pas que le traitement soit terminé pour continuer à interagir avec l'application.
Simplicité : Nous avons évité d'implémenter une solution plus complexe avec des queues ou autres outils de gestion de tâches asynchrones.
Contrôle : Nous avons la possibilité de gérer l'état des tâches (en cours, terminées, échouées) et de garder une trace des erreurs potentielles.
Cela étant dit, dans une application de plus grande envergure, il serait peut-être préférable d’implémenter une solution plus robuste et évolutive, comme une queue via Laravel ou des outils Python comme Celery, qui permettent de mieux gérer les processus longs et d’offrir plus de souplesse.
Le résultat : une mini web app fonctionnelle !
🎯 On envoie du texte, on choisit la langue et le modèle, et on obtient un fichier audio !
L’interface est propre et simple, et la génération est fluide et rapide. 🚀
Et après ?
Ce projet était un bon moyen de jouer avec Flask, d’expérimenter un TTS local et open source, et de créer un outil pratique et rapide à utiliser.
Si vous voulez tester par vous-même, voici le repo GitHub :
👉 Lien vers le projet
Et vous, avez-vous déjà tenté d’intégrer une synthèse vocale dans un projet ? 🤔 (Je sais, je sais… on n'a pas encore de section commentaire. Mais bon, tout vient à point à qui sait attendre… ou à qui a un peu de temps pour ajouter ça ! 😅